About this episode
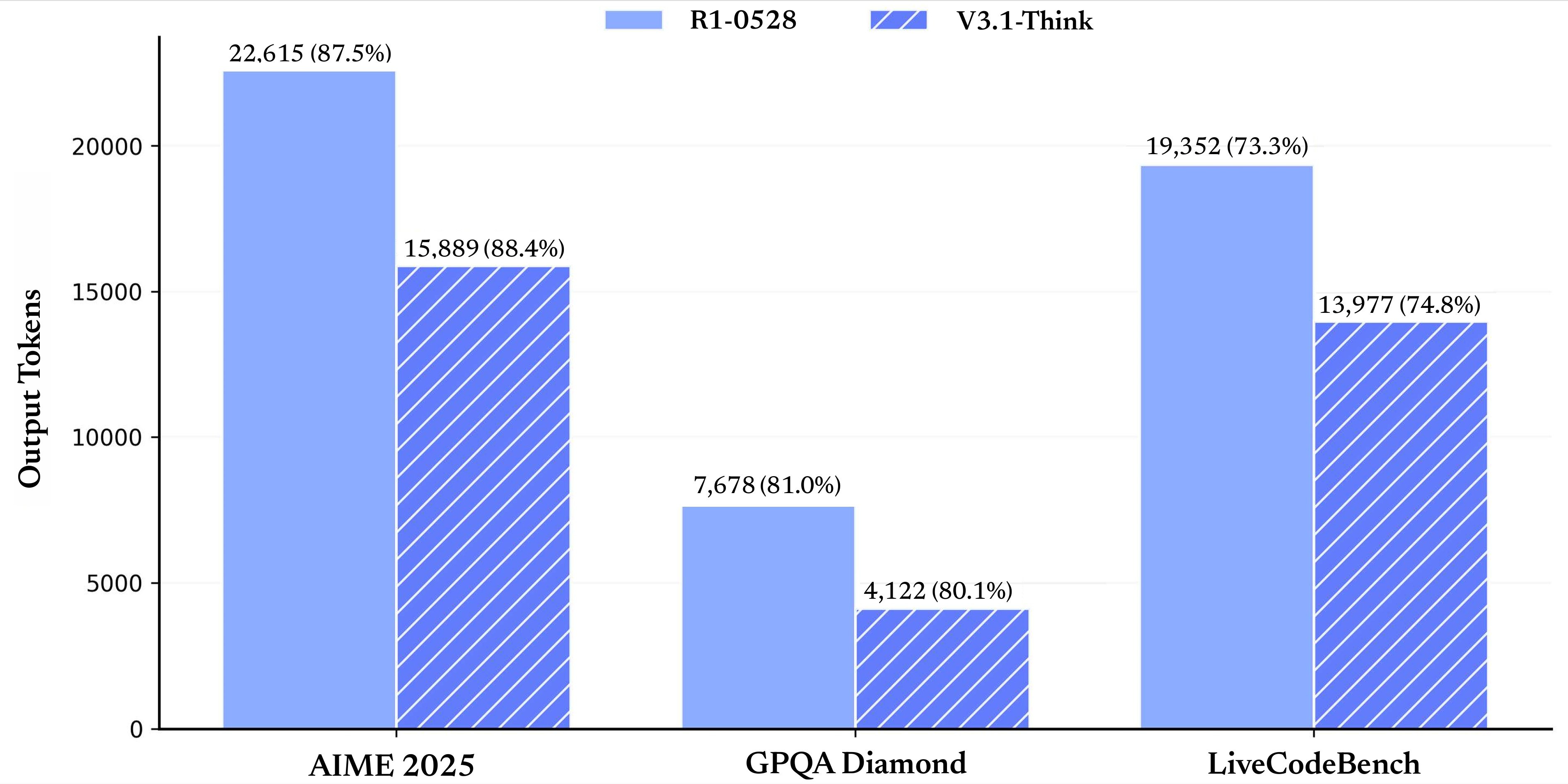
Hey everyone, Alex here ?This week looked quiet… until about 15 hours before we went live. Then the floodgates opened: DeepSeek dropped a hybrid V3.1 that beats their own R1 with fewer thinking tokens, ByteDance quietly shipped a 36B Apache-2.0 long-context family with a “thinking budget” knob, NVIDIA pushed a faster mixed-architecture 9B with open training data, and a stealth image editor dubbed “Nano Banana” started doing mind-bending scene edits that feel like a new tier of 3D-aware control. On the big-co side, a mystery “Sonic” model appeared in Cursor and Cline (spoiler: the function call paths say a lot), and OpenAI introduced Agents.md to stop the config-file explosion in agentic dev tools. We also got a new open desktop-agent RL framework that 4x’d OSWorld SOTA, an IBM + NASA model for solar weather, and Qwen’s fully open 20B image editor that’s shockingly capable and runnable on your own GPU.Our show today was one of the shortest yet, as I had to drop early to prepare for Burning Man ?? Speaking of which, Wolfram and the team will host the next episode! Ok, let's dive in! DeepSeek V3.1: a faster hybrid that thinks less, scores more (X, HF)DeepSeek does this thing where they let a base artifact “leak” onto Hugging Face, and the rumor mill goes into overdrive. Then, hours before we went live, the full V3.1 model card and an instruct variant dropped. The headline: it’s a hybrid reasoner that combines the strengths of their V3 (fast, non-thinking) and R1 (deep, RL-trained thinking), and on many tasks it hits R1-level scores with fewer thinking tokens. In human terms: you get similar or better quality, faster.A few things I want to call out from the release and early testing:* Hybrid reasoning mode done right. The model can plan with thinking tokens and then switch to non-thinking execution, so you don’t have to orchestrate two separate models. This alone simplifies agent frameworks: plan with thinking on, execute with thinking off.* Thinking efficiency is real. DeepSeek shows curves where V3.1 reaches or surpasses R1 with significantly fewer thinking tokens. On AIME’25, for example, R1 clocks 87.5% with ~22k thinking tokens; V3.1 hits ~88.4 with ~15k. On GPQA Diamond, V3.1 basically matches R1 with roughly half the thinking budget.* Tool-use and search-agent improvements. V3.1 puts tool calls inside the thinking process, instead of doing a monologue and only then calling tools. That’s the pattern you want for multi-turn research agents that iteratively query the web or your internal search.* Long-context training was scaled up hard. DeepSeek says they increased the 32K extension phase to ~630B tokens, and the 128K phase to ~209B tokens. That’s a big bet on long-con